Singular Value Decomposition - Rank
matrix
Recall that the basis of a vector space $\mathbb{V}$, $\left<\mathbf{v}_1, \mathbf{v}_2, \ldots, \mathbf{v}_n \right>$, are linearly independent and span $\mathbb{V}$. The number of basis vectors for vector space $\mathbb{V}$ is the dimension of $\mathbb{V}$.
A specific type of vector space, column space of matrix $\mathbf{A}$, is written as $\operatorname{col}(\mathbf{A})$. It is defined as the set of all linear combinations of the columns of $\mathbf{A}$, also written as $\mathbf{A}\mathbf{x}$.
Let $\mathbf{A}$ be an $m \times n$ matrix, with column vectors $\mathbf{v}_1$, $\mathbf{v}_2$, $\ldots$, $\mathbf{v}_n$.
$$ \begin{equation*} \mathbf{A} = \begin{bmatrix} \mathbf{v}_1 & \mathbf{v}_2 & \cdots & \mathbf{v}_n \\ \end{bmatrix} \end{equation*} $$
A linear combination of theses vectors is therefore
$$ c_1\mathbf{v}_1 + c_2\mathbf{v}_2 + \cdots + c_n\mathbf{v}_n, $$
where $c_1, c_2, \cdots, c_n$ are scalars. That is, the columns space of $\mathbf{A}$ $\operatorname{col}(\mathbf{A})$ is the span of the vectors $\mathbf{v}_1$, $\mathbf{v}_2$, $\ldots$, $\mathbf{v}_n$.
We also have
$$ \begin{equation*} c_1\mathbf{v}_1 + c_2\mathbf{v}_2 + \cdots + c_n\mathbf{v}_n = \begin{bmatrix} \mathbf{v}_1 & \mathbf{v}_2 & \cdots & \mathbf{v}_n \\ \end{bmatrix} \begin{bmatrix} c_1 \\ c_2 \\ \vdots \\ c_n \\ \end{bmatrix} = \mathbf{A}\mathbf{x} \end{equation*}, $$
where $\mathbf{x}$ is an $n \times 1$ vector, $$ \begin{bmatrix} c_1 & c_2 & \ldots & c_n \\ \end{bmatrix}. $$
Therefore, column space $\operatorname{col}(\mathbf{A})$ consists of all vectors in the form of $\mathbf{A}\mathbf{x}$. Like any other vector space, a column space also has basis vectors. The number of basis vectors for $\operatorname{col}(\mathbf{A})$, or the dimension of $\operatorname{col}(\mathbf{A})$ is called the rank of $\mathbf{A}$. In other words, the rank of $\mathbf{A}$ is the dimension of column space $\mathbf{A}\mathbf{x}$.
The rank of $\mathbf{A}$ is also the maximum number of linearly independent columns in $\mathbf{A}$. This is because we can write all the dependent columns as a linear combination of these linearly independent columns. Given that $\mathbf{A}\mathbf{x}$ consists of all possible linear combination of columns in $\mathbf{A}$, any member in $\mathbf{A}\mathbf{x}$ can also be written as a linear combination of these linearly independent columns. These linearly independent columns span $\mathbf{A}\mathbf{x}$ and form a basis for $\operatorname{col}(\mathbf{A})$, and the number of these vectors becomes the dimension of $\operatorname{col}(\mathbf{A})$ or rank of $\mathbf{A}$.
In the previous post on eigendecomposition, the rank of each projection matrix $\lambda_i\mathbf{u}_i\mathbf{u}_i^T$ is 1. Recall that each projection matrix only have one non-zero eigenvalue. This is not a coincidence. It can be shown that the rank of a symmetric matrix is equal to the number of its non-zero eigenvalues.
Let’s return to the eigendecomposition equation. Suppose that we apply our symmetric matrix $\mathbf{A}$ to an arbitrary vector $\mathbf{x}$. Now the eigendecomposition equation becomes:
$$ \begin{equation*} \mathbf{A}\mathbf{x} = \lambda_1\mathbf{u}_1\mathbf{u}_1^\top\mathbf{x} + \lambda_2\mathbf{u}_2\mathbf{u}_2^\top\mathbf{x} + \cdots + \lambda_n\mathbf{u}_n\mathbf{u}_n^\top\mathbf{x} \end{equation*} $$
Recall the important property of symmetrix matrices in the last post. An $n \times n$ symmetric matrix has $n$ real eigenvalues, as well as $n$ linear independent and orthogonal eigenvectors. These eigenvectors can be used as a new basis of a $n \times 1$ vector $\mathbf{x}$. In other words, a $n \times 1$ vector $\mathbf{x}$ can be uniquely written as a linear combination of the eigenvectors of $\mathbf{A}$
$$ \mathbf{x} = a_1\mathbf{u}_1 + a_2\mathbf{u}_2 + \cdots + a_n\mathbf{u}_n, $$
$$ \left[x\right]_B = \begin{bmatrix} a_1 \\ a_2 \\ \vdots \\ a_n \\ \end{bmatrix} $$
Recall that all the eigenvectors of a symmetric matrix are orthogonal. To find each coordinate $a_i$, we just need to draw a line perpendicular to an axis of $\mathbf{u}_i$ through point $\mathbf{x}$ and see where they intersect. Therefore, each coordinate $a_i$ is equal to the dot product of $\mathbf{x}$ and $\mathbf{u}_i$, and $\mathbf{x}$ can be re-written as
$$ \begin{equation*} \mathbf{x} = (\mathbf{u}_1^\top\mathbf{x})\mathbf{u}_1 + (\mathbf{u}_2^\top\mathbf{x})\mathbf{u}_2 + \cdots + (\mathbf{u}_n^\top\mathbf{x})\mathbf{u}_n \end{equation*} $$
Now if we multiply $\mathbf{A}$ by $\mathbf{x}$, we get:
$$ \begin{equation*} \mathbf{A}\mathbf{x} = (\mathbf{u}_1^\top\mathbf{x})\mathbf{A}\mathbf{u}_1 + (\mathbf{u}_2^\top\mathbf{x})\mathbf{A}\mathbf{u}_2 + \cdots + (\mathbf{u}_n^\top\mathbf{x})\mathbf{A}\mathbf{u}_n \end{equation*} $$
and since the $\mathbf{u}_i$ vectors are eigenvectors of $\mathbf{A}$, the last equation simplies to:
$$ \begin{align*} \mathbf{A}\mathbf{x} &= (\mathbf{u}_1^\top\mathbf{x})\lambda_1\mathbf{u}_1 + (\mathbf{u}_2^\top\mathbf{x})\lambda_2\mathbf{u}_2 + \cdots + (\mathbf{u}_n^\top\mathbf{x})\lambda_n\mathbf{u}_n \\ &= \lambda_1\mathbf{u}_1\mathbf{u}_1^\top\mathbf{x} + \lambda_2\mathbf{u}_2\mathbf{u}_2^\top\mathbf{x} + \cdots + \lambda_n\mathbf{u}_n\mathbf{u}_n^\top\mathbf{x} \end{align*} $$
which is the eigendecomposition equation.
Each of the eigenvectors $\mathbf{u}_i$ is normalized, so they are unit vectors. In each term of the eigendecomposition equation, $\mathbf{u}_i\mathbf{u}_i^T\mathbf{x}$ gives a new vector which is the orthogonal projection of $\mathbf{x}$ onto $\mathbf{u}_i$. Then this vector is scaled by $\lambda_i$. Finally all the $n$ vectors $\lambda_i\mathbf{u}_i\mathbf{u}_i^\top\mathbf{x}$ are summed together to give $\mathbf{A}\mathbf{x}$. This process is shown in Figure 1.
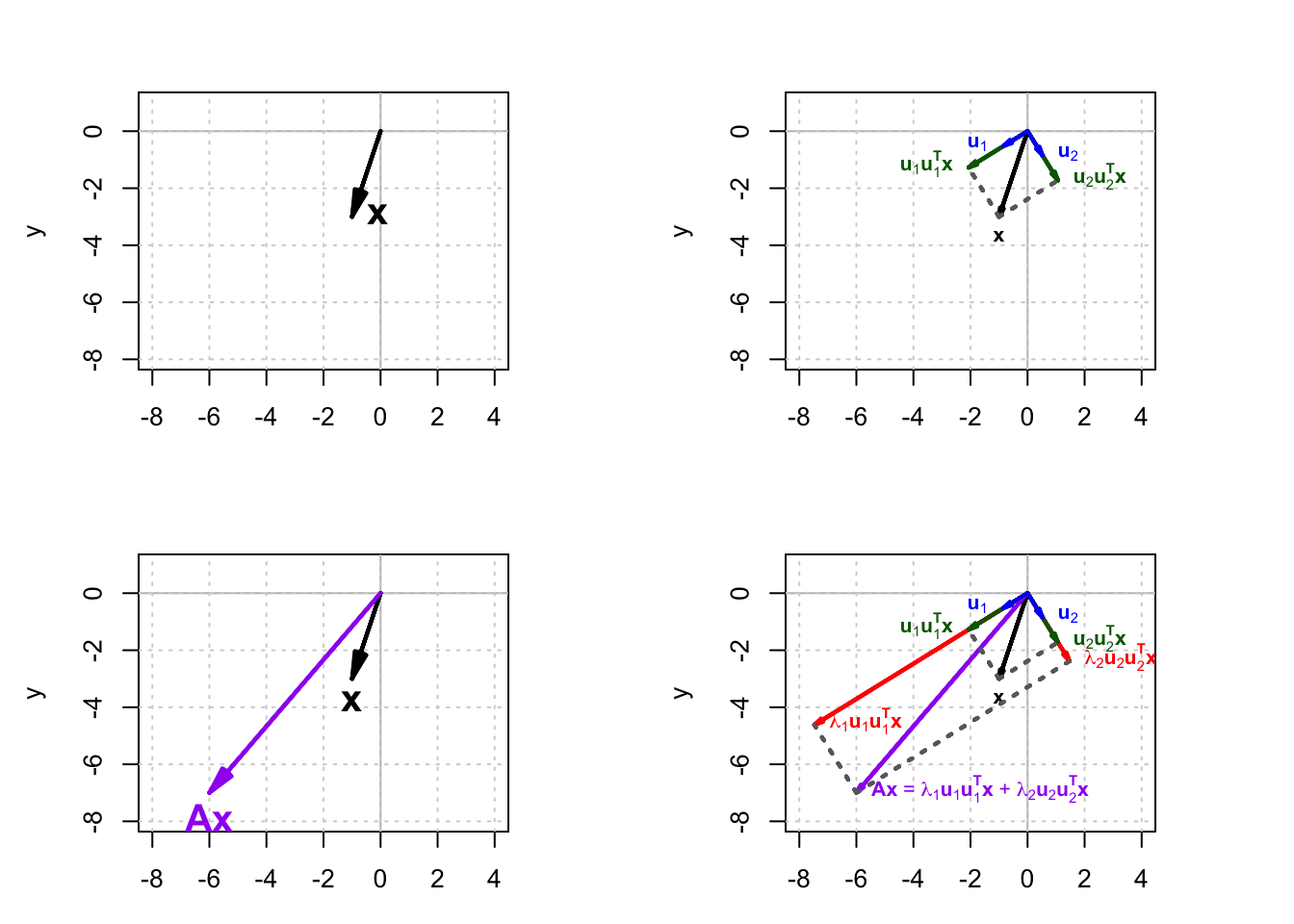
The eigendecomposition mathematically explains an important property of symmetric matrices that we have seen in the plots before. A symmetric matrix transforms a vector by stretching or shrinking it along its eigenvectors, and the amount of stretching or shrinking along each eigenvector is proportional to the corresponding eigenvalue.
In addition, the eigendecomposition can break an $n \times n$ symmetric matrix into $n$ matrices with the same shape ($n \times n$) multiplied by one of the eigenvalues. The eigenvalues play an important role here since they can be thought of as a multiplier. The projection matrix only projects $\mathbf{x}$ onto each $\mathbf{u}_i$, and the eigenvalue scales the length of the vector projection ($\mathbf{u}_i\mathbf{u}_i^\top\mathbf{x}$). The bigger the eigenvalue, the bigger the length of the resulting vector ($\lambda_i\mathbf{u}_i\mathbf{u}_i^\top\mathbf{x}$) is, and the more weight is given to its corresponding matrix ($\mathbf{u}_i\mathbf{u}_i^\top$).
We can approximate the original symmetric matrix $\mathbf{A}$ by summing the terms which have the highest eigenvalues. For example, if we assume the eigenvalues $\lambda_i$ have been sorted in descending order,
$$ \begin{equation*} \mathbf{A} = \lambda_1\mathbf{u}_1\mathbf{u}_1^\top + \lambda_2\mathbf{u}_2\mathbf{u}_2^\top + \cdots + \lambda_n\mathbf{u}_n\mathbf{u}_n^\top \end{equation*}, $$
$$ \lambda_1 \geq \lambda_2 \geq \cdots \geq \lambda_n $$
then we can take only the first $k$ terms in the eigendecomposition equation to have a good approximation for the original matrix:
$$ \begin{equation*} \mathbf{A} \approx \mathbf{A}_k = \lambda_1\mathbf{u}_1\mathbf{u}_1^\top + \lambda_2\mathbf{u}_2\mathbf{u}_2^\top + \cdots + \lambda_k\mathbf{u}_k\mathbf{u}_k^\top \end{equation*} $$
where $\mathbf{A}\mathbf{k}$ is an approximation of $\mathbf{A}$ with the first $k$ terms.
If in the original matrix $\mathbf{A}$, the other $(n - k)$ eigenvalues that we left out are very small and close to zero, then the approximated matrix in a very similar to the original matrix, and we have a good approximation.
Matrix
$$ \mathbf{C} = \begin{bmatrix} 5 & 1 \\ 1 & 0.35 \\ \end{bmatrix} $$
with
$$ \lambda_1 = 5.206,~\lambda_2 = 0.144 $$
$$ \begin{equation*} \mathbf{u}_1 = \begin{bmatrix} -0.979 \\ -0.202 \\ \end{bmatrix},~ \mathbf{u}_2 = \begin{bmatrix} 0.202 \\ -0.979 \\ \end{bmatrix} \end{equation*} $$
is an example. Here $\lambda_2$ is very small compared to $\lambda_1$. We could approximate $\mathbf{C}$ with its first term in eigendecomposition corresponding to eigenvalue $\lambda_1$. Let’s visualize this by applying $\mathbf{C}$ to vectors on a unit circle.
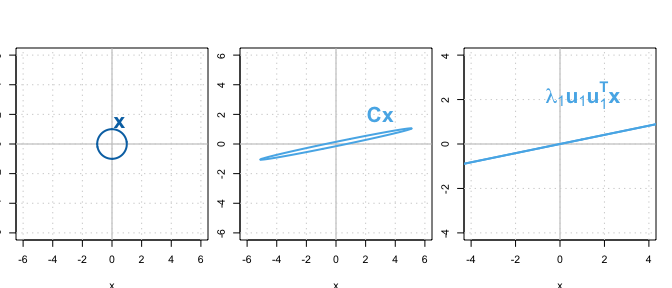
Multiplying $\mathbf{x}$ by $\mathbf{C}$ results in a very similar shape compared to multiplying $\mathbf{x}$ by $\lambda_1\mathbf{u}_1\mathbf{u}_1^\top$.
Keep in mind that a symmetric matrix is required for the eigendecomposition equation to hold. Suppose that you have a non-symmetric matrix:
$$ \begin{bmatrix} 3 & -1 \\ 1 & 2 \\ \end{bmatrix} $$
the eigenvectors are not linear independent, and the eigenvalues have both real and imaginary parts. Without real eigenvalues, we cannot properly scale projected vectors.
Or consider another non-symmetric matrix:
$$ \begin{bmatrix} 3 & 2 \\ 0 & 2 \\ \end{bmatrix} $$
Here the eigenvectors are linearly independent, but are not orthogonal, and they do not show the correct direction of stretching after transformation.
The eigendecoposition method is very useful, but only works for a symmetric matrix. A symmetric matrix is always a square matrix. If you have a non-square matrix, or a square but non-symmetric matrix, then you cannot use the eigendecomposition method to approximate it with other matrices. Singular Value Decomposition overcomes this problem, which will the topic of our next post.